




Introduction
DevOps monitoring teams consistently focus on more features and quality upgrades or perfect automated releases. Traditional DevOps monitoring approaches are good at observing basic metrics. But finding an infrequent anomaly is hard, as well as being able to predict failure before it happens!
DevOps Monitoring enables the technologies to find patterns in the vastness of operational data. They analyze that humans might miss, thereby enabling predictive maintenance and providing actionable alerts for faster incident resolution.
They are not just speeding up the monitor; they are also helping to make it more precise. ML models enable historical learning based on previous data to gradually increase the accuracy of detection and also recommend preventive measures before problems worsen.
In this blog, we will lift the curtains on how AI and ML make DevOps monitoring better, right from predictive analytics to automatic anomaly detection, which can be a game-changer for modern development and operations teams.
Early Problem Detection through Predictive Analytics
Predictive analytics is one of the most important applications of AI in DevOps monitoring. Rather than sitting around for an issue to happen, predictive models can uncover precursors in system performance that may lead to an outage before they occur. This enables the DevOps Teams to move from firefighting to prevention, spot possible failures at a very early stage.
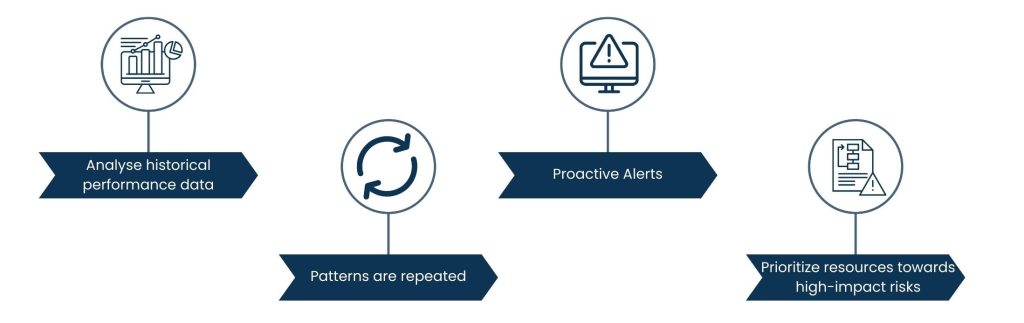
The following are suggestions that would effectively help DevOps Monitoring teams to use Predictive Analytics:
- Analyse historical performance data: Teach machine learning models (employing logs, metrics, past incident records) to know how systems behave normally.
- Patterns are repeated: If you see a typical pattern that precedes the failure itself, a continued increase in CPU utilization, a memory leak, or response times increasing over days or weeks.
- Proactive Alerts: Alert engineers automatically before the limits are reached, and they will react ingeniously right away, so that the customer will not be impacted.
- Prioritize resources towards high-impact risks: Use risk scoring to help you immediately home in on the factors that are about to materialize into service failures or revenue losses.
Turning DevOps Monitoring from Reactive to Proactive with Predictive Analytics:
The benefit of predictive analytics is its speed. As it allows companies to crunch vast volumes of operational data at a higher rate than a typical team could. Also, an AI-based monitoring tool can notice that a database query is getting slower by milliseconds on each passing day. Engineers optimize the query or make resource allocation adjustments. Before users spot a performance bug by spotting the trend early.
This further aids in capacity planning by measuring predictive analytics. By predicting in advance when the systems will hit their capacity based on traffic trends. Teams can increase infrastructure before it’s too late, and there is no time left for handling a high load. This enables optimal resource allocation and reduces the likelihood of expensive downtime during peak request periods.
Used as part of a larger DevOps monitoring strategy, predictive analytics is a bigger bang for the buck. Reduces downtime, lowers operational costs by avoiding the escalation that causes emergency fixes, and improves customer satisfaction. New predictions train the model while ongoing services are being provided. Assuming more data is processed through the machine learning models. Then, over time, those predictions can become even more accurate.
When you start thinking about predictive analytics, you are taking monitoring from hindsight to insight. And it permits the DevOps team to react before anything bad happens, turning monitoring into a modern tool with information. Not only on what happened, but with insights regarding what is possible that will happen soon. So that before it may appear odd, flex role you widespread the word!
Real-Time Anomaly Detection using Machine Learning with DevOps Monitoring
DevOps monitoring offers an active machine learning model to operate on data, and, considering the scale of big data, ML algorithms are good at detecting anomalies in large datasets. Real-time anomaly detection allows teams to immediately catch issues with even those whose failures may not conform to known failure patterns.
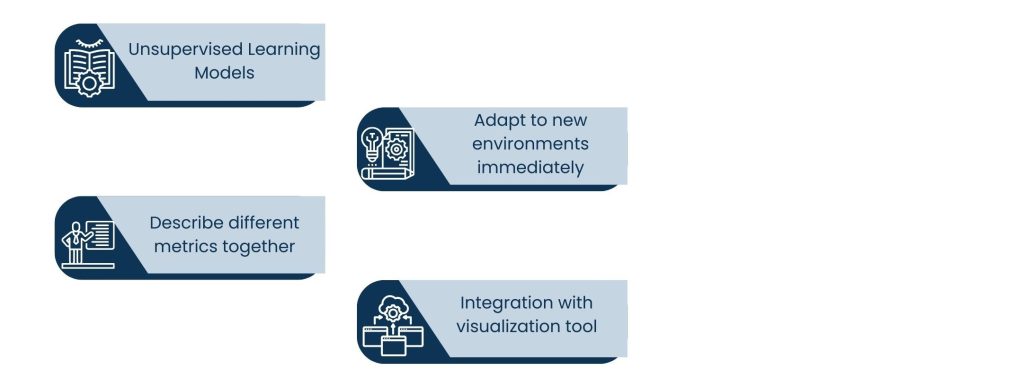
For devOps monitoring teams to achieve real-time anomaly detection deployment, they should:
- Unsupervised Learning Models: They discover weird patterns without predefined rules, thus best used for alerting on new issues that haven’t been seen before.
- Adapt to new environments immediately: By adjusting the sensitivity of a detection based on changes in your workloads, time of day, or even seasonal patterns, you reduce unnecessary noise from false alarms.
- Describe different metrics together: CPU, memory, network, with application logs to allow developers to have a context around anomalies.
- Integration with visualization tool: It must display the anomalies on dashboards that you can immediately understand & act on.
Now, let’s consider the following:
A very low traffic period where latency goes from 1 ms to 5 ms, which might be flagged (as unusual) as an incident due to the AI system. However, in the absence of an anomaly detection system, this goes unnoticed till it creates a large-scale outage.
The Real-Time Anomaly Detection in Security recognizes suspicious logins, unusual network activities, and unauthorized configuration changes. Threats that are often missed by traditional monitoring tools, so teams can respond immediately before it is too late.
AI detection evolves via learning, which is one of the key advantages. This process improves the system over time at separating rare events from signals of note. It reduces alert fatigue because if a notification fires, it is something that should be paid attention to.
Hence, real-time anomaly detection in their DevOps pipeline protects them from any significant performance degradation and potential security liabilities. Letting the developers continue to ensure that it is being maintained in terms of system reliability as well as user confidence.
Smart Alerting and Noise Control with DevOps Monitoring
One of the common challenges in monitoring is alert fatigue in DevOps. An alert may go unnoticed when hundreds of messages are being issued every hour. Whereas if you reduce this to around 5-10 alerts, then it would be much more beneficial. AI and machine learning enable filtering alerts to get important notifications; they can be grouped and prioritized.

Strategies for intelligent alerting include:
- Alerts correlation: Aggregate similar alerts of the same root cause into a single incident, minimizing noise level.
- Priority-based alerts: Prioritize In Use alerts based on impact analysis by showing the biggest problems first.
- Improving mistakes from historical resolutions: Teach your models about common false positives and automatically suppress them.
- Tailored Alerts: Send role-based alerts such as tech only and for the relevant data per team.
So, rather than firing off 50 individual error logs from a single API that failed, an AI solution may group them into one alert that identifies the root issue and potential solutions.
This reduction in noise means engineers can react more rapidly and with better tune, improving mean time to resolution. Eventually, the alerting system learns to match the nature of the organization and has gotten better at not sending irrelevant data.
This way, intelligent alerting ensures your teams are not wasting time on cat-and-mouse with false alarms but productive work, while at the same time keeping your systems up and running.
Also Read: Compliance Automation for Small Businesses
The AI approach to speed up Incident Response with DevOps Monitoring
Detection is the first part of monitoring in DevOps, but speed to resolution also plays an essential role. AI, however, can make a real difference in incident response by leading teams through the troubleshooting process, automating fixes (if possible), and thereby cutting down on downtime considerably.

Teams can enhance their incident response with AI by:
- Automate root cause analysis: Use AI to analyze logs, performance metrics, and recent changes to get an idea of where the probable source of issues is.
- Recommend remediation: Suggest high-level recommendations that are based on previous similar incidents and their proven fixes.
- To trigger certain automated workflows: When there are known problems that come up again and again in networks, routers can be programmed to run predefined scripts. Which will remediate most such problems on their own without waiting around for a human to intervene.
- Post-incident tracking and learning: Feed post-incident insights back through the AI model to enhance future responses.
If the performance of a workload declines significantly because a load balancer is misconfigured, AI could detect that misconfiguration and provide advice on optimal settings, even automatically correcting the initial configuration based on existing approval workflows.
This not only reduces downtime itself but also makes teams feel more confident in dealing with incidents. The automation of menial tasks releases more engineers to focus on the higher-level, human-friendly problems, which are best for productivity and morale.
DevOps Monitoring with Continuous Learning and Improvement
When it comes to DevOps monitoring, AI has the most significant pro, which automates learning and adaptation. In AI-powered systems, unlike static monitoring solutions, the accuracy increases over time as they process more operational data and feedback.

DevOps teams can leverage continuous learning by:
- Keep models fresh: Constantly feed new metrics, logs, and incident data to the model to avoid it going stale
- Include post-mortem analysis: Feed insights from incident review back into the system to prevent a recurrence.
- Dynamically update baselines: as workloads shift and the season changes, so too should your “normal” operating parameters.
- Utilize engineer feedback loops: Enable users to tag alerts as true/false, improving future alert accuracy.
For example, if a previously unknown network limitation is encountered, the system can adjust its alerting criteria. Such that similar patterns are rapidly detected in the future.
The learning element informs how to better detect and respond. As well as adjusting to changes in infrastructure, scaling services out or up, deploying new technologies, and moving towards cloud-native architectures.
Placing learning and adaptation into monitoring enables a DevOps team to be proactive in tackling issues. And also respond quickly to novel errors, and maintain system stability, especially in an environment that changes constantly.
Improving Observability using AI in DevOps Monitoring
Observability is not only about monitoring, but it is specifically related to the capability. That is provided for understanding the internal states of a system based on its output. AI in DevOps monitoring truly creates a metadata stack that gets more change to your observability with deeper insights. Additionally, clearer correlations & you shrink blind spots significantly.

There are things that a well-designed AI-driven observability setup would look like:
- Global data integration: AI enables telemetry from logs, metrics, traces, and user experience into a unified analytical model.
- Root-cause mapping within context: Through ML, we can understand how varying components of the system affect each other more quickly and diagnose multi-layered issues faster.
- Adaptive visualizations: AI can offer the most appropriate data views according to the incident being detected at that time, helping engineers concentrate on prioritized items.
- Correlating with historical trends: This helps match past incidents with current anomalies to help teams go back and know how these incidents can be fixed.
AI, for example, can identify the cause and effect behind everything that has been happening in your stack. Recent code commit, infrastructure change, database query performance, etc., within seconds. In case the app is showing high latency, without manually having to dig into all of these various sources.
This is even more critical when you have microservices or cloud-native architecture. Where you could easily have hundreds of components communicating with each other. If an organization handpicked all its data to trace the same cause for errors, it may again take hours, but with AI, that would be minutes or even seconds.
But AI-powered observation helps Environment DevOps teams work together. Most businesses will gain really valuable contextual insights for non-technical stakeholders out of the box. Helping them to understand the broader impact incidents are having on customer experience and business outcomes, and inform fast decision-making and prioritization.
DevOps teams can see more, and just as importantly, comprehend more by blending observability with AI. That insight is a golden nugget in a world where the value of every one-minute downtime can reach up to thousands.
Steps to Overcome Challenges and Best Practices by DevOps Monitoring
The advantages of AI in DevOps monitoring are many, but putting it into practice presents some hurdles. Teams, without planning enough, run the danger of adding complexity.
Key challenges include:
- Problems with data quality: AI will be as good as the data it learned.
- Predictions can be wrong: Inaccurate, inconsistent, or noisy datasets going in will produce skewed results.
- Overhead of model training: Keeping the models accurate and up to date is costly in terms both time, computing resources, and staffing.
- Alert-fatiguing: Models that are too sensitive may alert incessantly.
- Complexity in integration: There are some technical challenges associated with integrating AI tools with your existing DevOps pipeline.
Some of the best practices to solve these challenges are as follows:
- Pilot first: Start with the whispers of AI in one area of monitoring (i.e., anomaly detection) before running further.
- Leverage hybrid monitoring: marry AI-driven insights with human review to ensure behavioral integrity.
- Automate feedback loops: Have engineers tag alerts, so the AI learns continuously.
- Explain it: Use tools that produce AI decisions transparently, meaning engineers can see exactly why and how AI made its decisions.
The coming of AI in DevOps monitoring is no magical elixir for all your pain points. AI can become self-sustainable, shorn of the friction; only once we start with a real-life small battle, refine our models in the light of actual outcomes, and sync deadlocks between DevOps and data science while deploying it as hard.
When it is deployed correctly, AI does not simply make up for better monitoring: it elevates that monitoring to the level of prediction and adaptation to learn from past mistakes, resulting in increased uptime, quicker releases, and higher customer satisfaction.
Conclusion
The move is made better with the rise of AI and machine learning, a technology that just happens to address many of the current woes everyone faces in DevOps monitoring: it ends up reactive and could use some proactiveness; it must be smart enough to know about problems without alerting to everything. Predictive analytics, real-time anomaly detection, intelligent alerting, and AI-assisted incident resolution now ensure that DevOps can maintain system health even under the most demanding workloads.
It is not just about the speed or efficiency that we can get. Intelligent monitoring: AI-driven monitoring that teaches and customizes itself over time to the changes in capacities, technology, or behaviour. This ensures that monitoring practices always remain current and are not left behind in the changing environment.
Organizations that adopt AI and machine learning will have the power to gain a competitive edge as demand for DevOps monitoring grows and customer standards skyrocket. The teams that adapt these technologies today will not only decrease downtime and operating expenditures in the future, but they will do so from a position of confidence, giving them the ability to respond with more agility and deploy innovation more efficiently, tomorrow.
About Us
Tasks Expert offers top-tier virtual assistant services from highly skilled professionals based in India. Our VAs handle a wide range of tasks, from part time personal assistant to specialized services like remote it support services, professional bookkeeping service etc. Furthermore, it helps businesses worldwide streamline operations and boost productivity.
Ready to elevate your business? Book a Call and let Tasks Expert take care of the rest.

About Author

Gary Katz
Related Blogs


